
OpenAI’s Sora has captured the imagination of creators everywhere. This groundbreaking model takes simple text descriptions and transforms them into captivating short videos, pushing the boundaries of AI-powered creativity. But what lies beneath the surface of this technological marvel? Let’s delve into the fascinating world of text-to-video generation and explore the technical complexities that power Sora.
Running a model as sophisticated as Sora requires immense computational resources. A single image contains millions of data points, but a one-minute video at 60 frames per second balloons to over 10 billion!
A Technical Breakdown
Training on a Mountain of Data
Imagine feeding Sora a massive library of videos and images, each paired with detailed captions. That’s exactly how this AI whiz kid learns! This vast amount of data allows Sora to understand the intricate relationships between words, visuals, and movement.
Patching Things Together
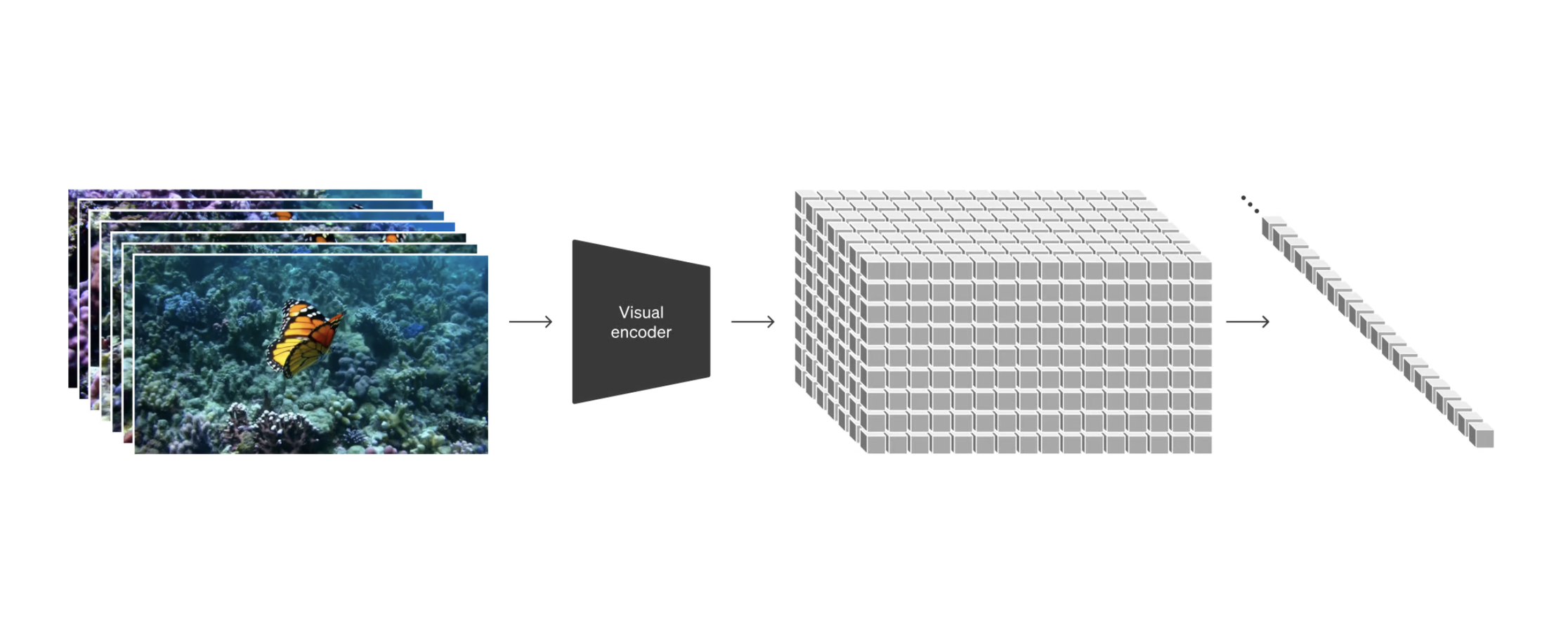
Visual representation of turning video frames into patches
Sora utilises a unique technique called “patch-based representation.” Think of chopping a video into tiny squares, each containing a snapshot of a specific moment. These “patches” become Sora’s building blocks. The beauty of this approach is its flexibility. Sora can handle videos of various lengths, resolutions, and even different aspect ratios (think widescreen vs. vertical phone videos) – all by arranging these patches in different ways.
Transformers; The Powerhouse Behind the Scenes
Remember how Sora understands the relationships between words in a text prompt? This is powered by a sophisticated AI architecture called a transformer. Similar to how a skilled translator interprets languages, the transformer decodes the meaning and context of the text description, guiding Sora in generating a visually coherent video.

Diffusion transformer denoising video with each training iteration
The Power of Computation
The researchers behind Sora discovered that the key to unlocking its full potential lies in training on ever-increasing amounts of data with ever-growing computational resources. The more data and processing power Sora has, the more nuanced and realistic its video creations become.
Emerging Simulator Capabilities
One of the most exciting aspects of Sora is its potential to become a powerful simulator of the real world. While still under development, Sora exhibits some remarkable abilities:
- 3D Consistency: Picture a video with a moving camera. Sora can generate scenes where objects and people move realistically through a 3D space, even as the camera angle changes.
- Long-range Coherence: Maintaining consistency in long videos can be challenging. Sora demonstrates the ability to keep track of objects and characters, even if they disappear from the frame for a while.
- Simulating Interactions: In some instances, Sora can even simulate simple interactions within the video. Imagine a character painting on a canvas, and the painting progressively gets more complete with each frame.
The Future of Simulation, Beyond Imagination
The capabilities of Sora represent a significant leap forward in AI-powered simulation. As the technology matures and scales further, we can expect even more impressive feats, like:
- Accurate Physics Simulation: Imagine a video of a ball bouncing realistically, following the laws of physics.
- Complex Object Interactions: Sora might be able to simulate more intricate interactions, like objects breaking or liquids flowing.
References
- Video generation models as world simulators - https://openai.com/research/video-generation-models-as-world-simulators
- Tulyakov, Sergey, et al. “Mocogan: Decomposing motion and content for video generation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
- Peebles, William, and Saining Xie. “Scalable diffusion models with transformers.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
- Betker, James, et al. “Improving image generation with better captions.” Computer Science. https://cdn.openai.com/papers/dall-e-3.pdf 2.3 (2023)
Stay Tuned, The Story Continues
The development of text-to-video generation is a rapidly evolving field. Subscribe to What’s up with AI, to keep yourself updated on the latest advancements in Sora and other innovative AI projects.
In the meantime, if you’re interested in learning more about the specific technical advancements, I can provide resources for further exploration.
Let me know if you’d like to delve deeper into any specific technical aspects or research areas!