
Hold onto your hats, tech wizards and art enthusiasts, because Stable Diffusion 3 just blew the doors off AI image generation. We’re not just talking about subtle tweaks here – this is a full-blown revolution in speed, quality, and the very way these AI models bring your artistic visions to life.
The Need for Speed (and Resolution)
Let’s face it, waiting for an AI to paint your masterpiece can feel longer than watching paint dry in real life. Traditional diffusion models, while capable of generating stunning imagery, have been notorious for their lengthy render times, especially as you crank up the resolution and complexity.

The culprit? It’s all about the process. These models rely on a clever but computationally intensive technique called “denoising.” Picture this: you start with pure, chaotic noise (think static on a TV screen) and then gradually refine it, step-by-step, into a coherent image. It’s like chiseling a sculpture out of a block of marble, pixel by pixel. Effective? Absolutely. Efficient? Not so much.
Shifting Gears with Rectified Flow
Stable Diffusion 3 throws a wrench in the gears – in a good way, of course. It ditches the winding path of denoising in favor of a more direct approach: Rectified Flow. Instead of taking the scenic route, SD3 charts a straight-line course from random noise to your final image.
The research paper \[1] gets a bit technical, explaining that Rectified Flow “defines the forward process as straight paths between the data distribution and a standard normal distribution.” But the takeaway is this: faster generation times without sacrificing quality.
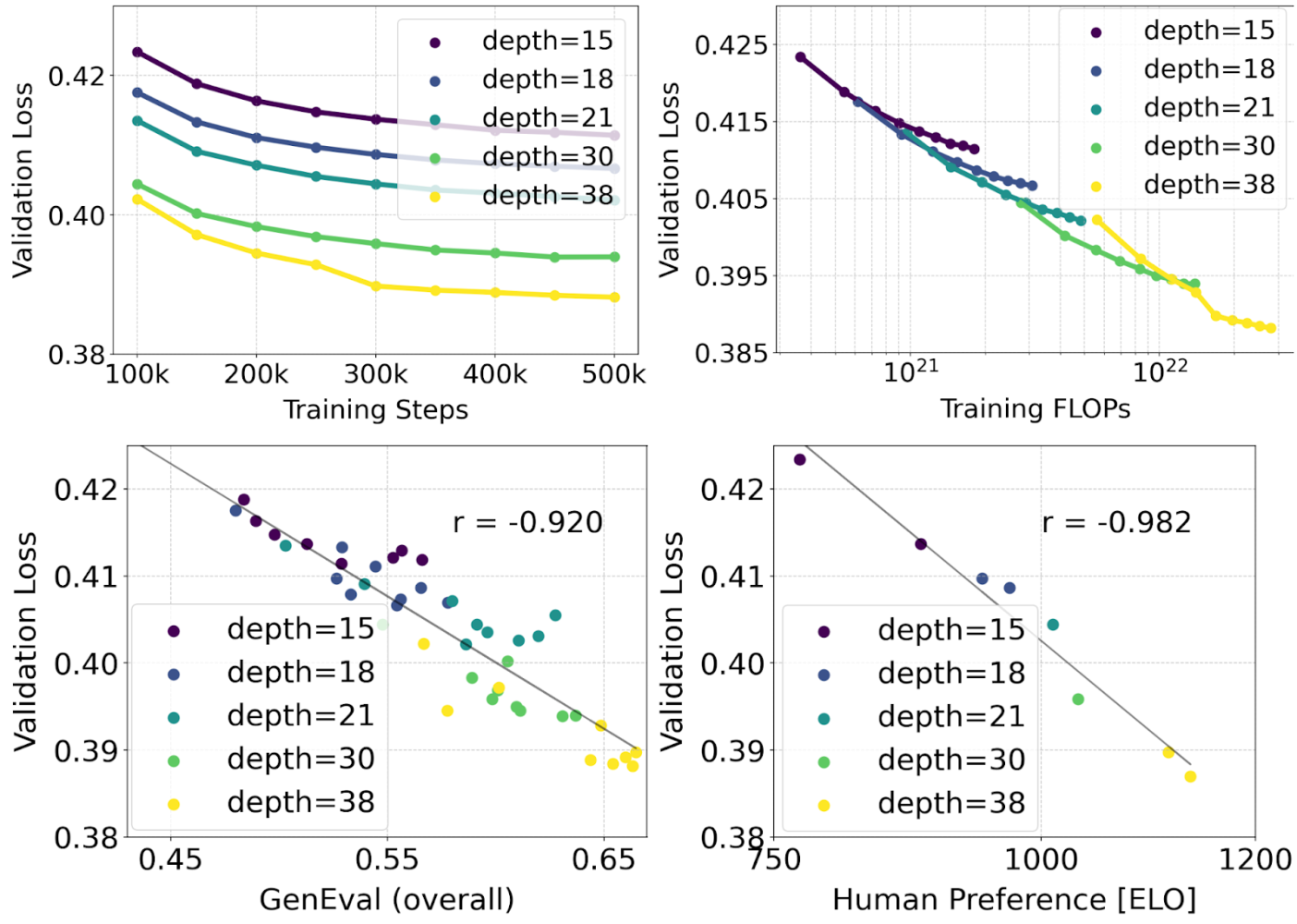
Scaling Rectified Flow Transformer Models
But speed isn’t everything – what about the art itself?
SD3 doesn’t disappoint. The research paper is brimming with impressive results, demonstrating significant improvements in key areas like:
High-Resolution Synthesis: SD3 handles those pixel-packed images like a champ, producing stunning results even at resolutions previously unimaginable for diffusion models.

Text Rendering and Comprehension: Ever try getting an AI to write legible text in an image? It’s often a recipe for hilarious (and frustrating) results. SD3 takes a giant leap forward in this area, generating clearer, more accurate text within its creations.
The Rise of Multimodal Diffusion Transformers (Beyond U-Nets)
Traditional diffusion models have often relied on U-Net architectures, which excel at capturing spatial features in images. While effective, U-Nets can struggle with the unique challenges of text-to-image generation, where the model must not only understand visual information but also interpret and translate complex language prompts into coherent imagery.
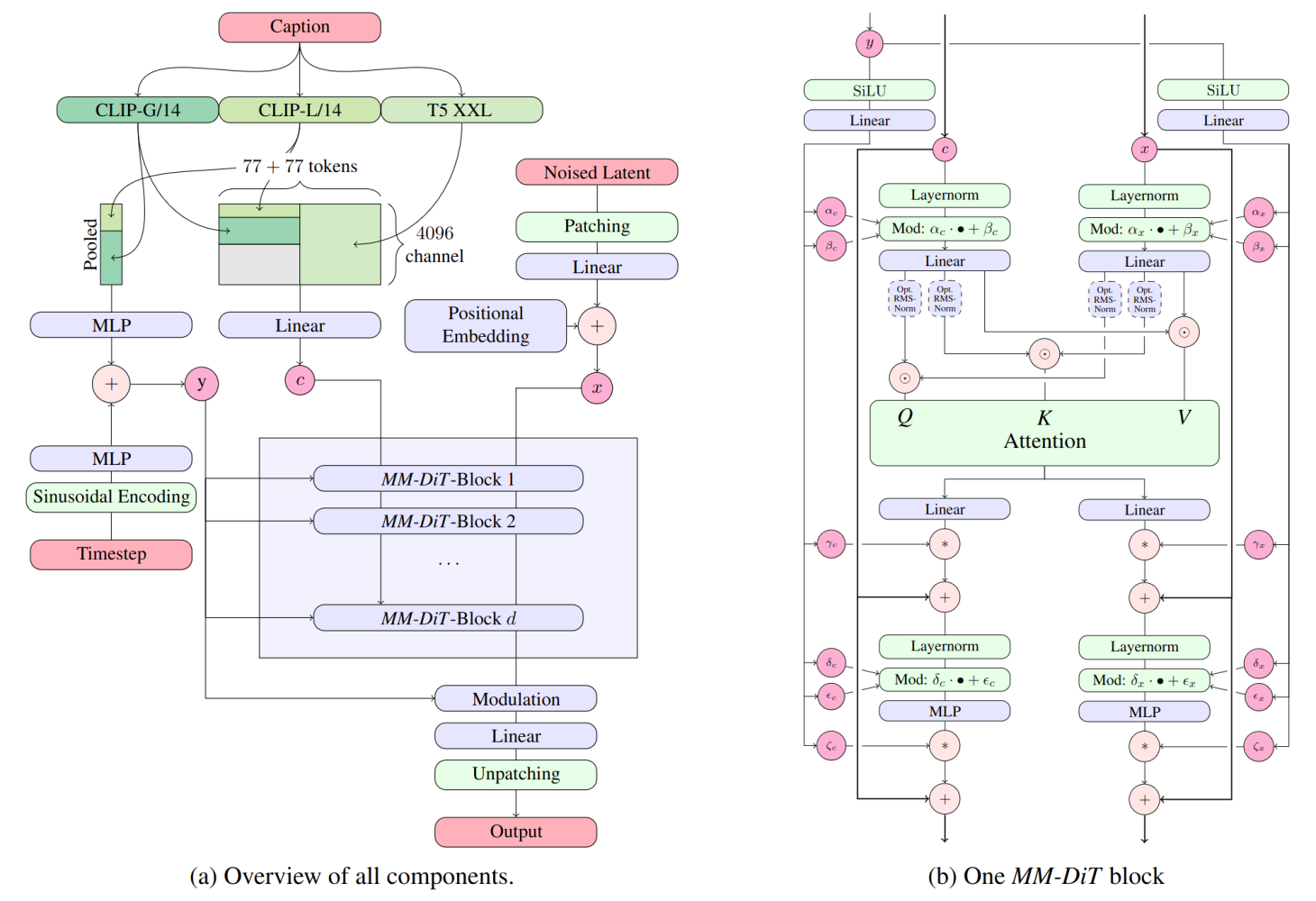
The RMS-Norm for Q and K can be added to stabilize training runs.
Stable Diffusion 3 throws down the gauntlet with MM-DiT, short for Multimodal Diffusion Transformer. This custom-designed architecture is specifically tailored to the intricate dance between text and images, orchestrating a seamless fusion of these distinct data streams.
Dual Pathways for Text and Image Mastery
The key to MM-DiT’s power lies in its ability to handle text and image data separately. Imagine it as a dual-core processor, where each core is optimized for a specific task. Instead of forcing both modalities through the same processing pipeline, MM-DiT creates dedicated pathways, allowing each data type to be analyzed and transformed with greater precision.
The research paper \[1] explains how MM-DiT employs “two separate sets of weights for the two modalities, which enables a two-way flow of information between them.” This bi-directional communication ensures that the model not only understands the individual elements of text and imagery but also grasps the intricate interplay between them.

Deciphering the Nuances of Language
MM-DiT doesn’t stop at separate pathways. It takes things a step further by incorporating multiple text encoders, often even three! This is like equipping your AI artist with a multilingual dictionary, allowing it to decipher the subtlest shades of meaning within your prompts.
Whether you’re crafting detailed descriptions, requesting specific styles, or whispering cryptic commands, MM-DiT’s multi-encoder arsenal ensures that SD3 captures the full richness of your creative intent.
The Challenge of Training a Text-to-Image Titan
Building a massive AI model like SD3 is a monumental undertaking. It’s like constructing a skyscraper, not just a modest dwelling. The researchers had to grapple with several key challenges to train SD3 effectively:
Data Preprocessing and Efficiency: To feed the model’s insatiable appetite for data, they meticulously curated and pre-encoded massive image datasets, optimizing for both quality and computational efficiency.
High-Resolution Mastery: SD3 is designed to handle high-resolution images, producing stunning results even at resolutions that would have crippled previous diffusion models.
Preventing Memorization: The researchers implemented clever techniques to prevent SD3 from simply memorizing training data, ensuring that it truly learns to generate novel imagery.
SD3 vs. the World (Benchmarking Brilliance)
The research paper \[1] is packed with evidence of SD3’s exceptional performance. It consistently outperforms previous open-source models on industry benchmarks like GenEval and T2I-CompBench, demonstrating superior prompt comprehension and compositional abilities.
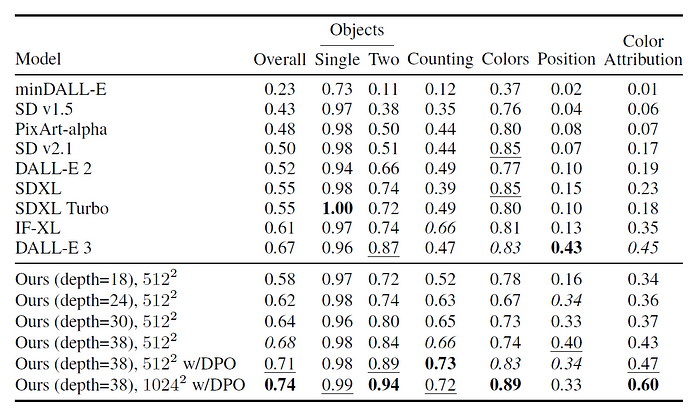
But the true test of any AI art generator lies in its ability to satisfy human aesthetic sensibilities. The researchers conducted extensive human preference evaluations, pitting SD3 against other leading models, including proprietary giants like DALL-E 3. The verdict? SD3 consistently ranked high in visual aesthetics, prompt adherence, and its remarkable ability to render accurate and legible text within its creations.
Architecting the Future of AI Art
Stable Diffusion 3’s MM-DiT architecture is a testament to the power of specialized design in AI. By tailoring the model to the specific demands of text-to-image generation, MM-DiT unlocks a new level of quality, control, and creative potential, setting a high bar for future AI artists and ushering in a new era of collaborative creativity between humans and machines.
\[1] Esser, Patrick, et al. “Scaling Rectified Flow Transformers for High-Resolution Image Synthesis.” (2024) - https://arxiv.org/abs/2403.03206