
The world of large language models (LLMs) is in a constant state of evolution, and Anthropic’s recent unveiling of Claude 3 marks a significant leap forward. This trio of AI models – Opus, Sonnet, and Haiku – boasts a diverse skillset and impressive technical capabilities. Let’s delve deeper into the inner workings of Claude 3 and explore what sets it apart.
The Brains Behind the Brawn: Transformer Architecture and Beyond
Like most contemporary LLMs, Claude 3 utilises a Transformer architecture. This deep learning model excels at analysing sequential data, such as text and code, by establishing relationships between words or code elements within a sequence. However, Claude 3 incorporates several advancements that enhance its performance:
- Sparse Attention: Traditional Transformers consider all elements within a given input sequence. Sparse attention allows Claude 3 to focus only on the most relevant parts of the input, significantly improving efficiency during training and inference (generating outputs).
Imagine you’re reading a complex scientific paper. A standard LLM would have to meticulously analyse every sentence. Sparse attention, however, allows Claude 3 to prioritise key findings and relevant sections, saving time and processing power.
- Reversible Transformer Layers: Training LLMs often involves a technique called backpropagation, where the model adjusts its internal weights based on the difference between its predicted output and the actual outcome. Reversible layers streamline this process by allowing for efficient backpropagation, leading to faster training and improved performance.
Beyond Text-to-Text: Unveiling Claude 3’s Diverse Skillset
While text generation is a core strength of LLMs, Claude 3 demonstrates an impressive range of capabilities:
- Code Generation: Struggling with that elusive line of code? Claude 3 can assist by generating different creative text formats, including code snippets. Programmers can leverage this functionality to streamline their workflow and explore alternative solutions.
- Question Answering with Real-World Knowledge Access: Unlike some LLMs confined to pre-loaded datasets, Claude 3 can access and process real-world information through Google Search. This empowers it to answer your questions with a foundation in factual accuracy.
- Long Context Recall: Traditional LLMs often struggle to retain information from extended conversations or complex prompts. Claude 3 demonstrates an improved ability to remember details from longer interactions, making it a valuable tool for tasks requiring a comprehensive understanding of context.
A Look at the Competition: Claude 3 vs. GPT-4 and Gemini Pro 1.5
The LLM landscape is a competitive space. Here’s a breakdown of how Claude 3 stacks up against other leading contenders:
- OpenAI’s GPT-4: Renowned for its impressive text generation capabilities and ability to adapt to different writing styles, GPT-4 has garnered significant attention. However, concerns exist around its potential for generating biased or misleading content.
- Google’s Gemini Pro 1.5: Details about Gemini Pro 1.5 remain somewhat shrouded in secrecy. While limited information suggests strong performance in text-to-code generation and reasoning tasks, a comprehensive comparison is challenging due to the lack of publicly available information.
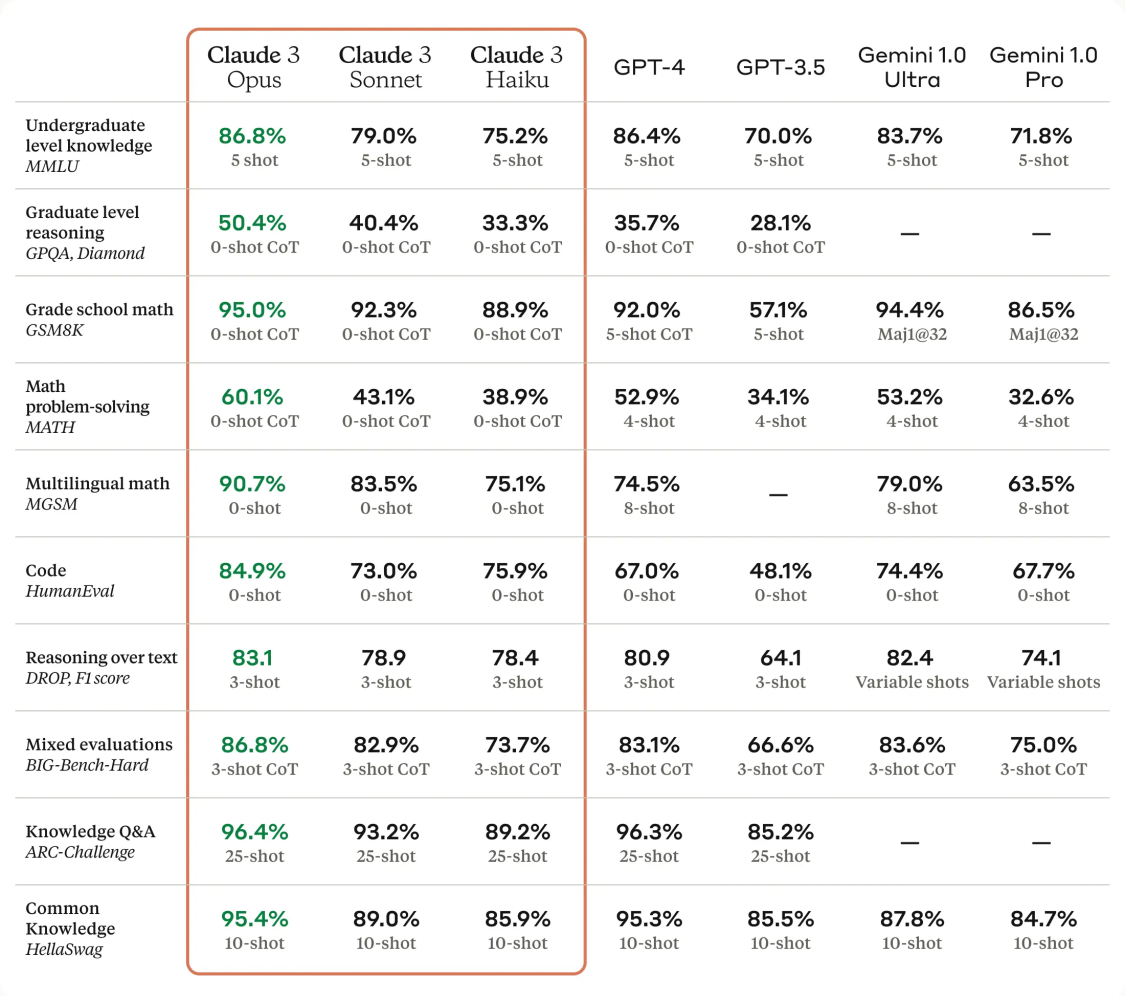
Technical Specifications: A Deep Dive
Understanding the technical underpinnings of Claude 3 necessitates a deeper look at its architecture:
- Model Size: The size and complexity of an LLM heavily influence its capabilities. While specific details about Claude 3’s model size haven’t been disclosed, Anthropic has confirmed it offers a range of models catering to different needs. Opus, the most powerful model, likely boasts a parameter count in the hundreds of billions, similar to other leading LLMs.
- Dataset: The quality and quantity of training data significantly impact an LLM’s performance. Claude 3 is trained on a massive dataset of publicly available internet text, along with data from public data labeling services and synthetically generated data. This diverse dataset contributes to Claude 3’s broad range of abilities.
The Future of Claude 3: Pushing the Boundaries of AI
Claude 3’s release marks a significant step forward, but the future holds even more exciting possibilities:
- Fine-tuning for Specific Tasks: Claude 3’s adaptability can be further enhanced by fine-tuning it for specific domains, like scientific research or creative writing. Imagine a specialised medical research assistant LLM trained on vast medical datasets and research papers.
- Ethical Considerations: As with any powerful technology, the ethical implications of LLMs require careful consideration. Anthropic’s focus on safety and responsible development ensures Claude 3 is used for good, pushing the boundaries of AI in a way that benefits society.